
El Último Examen de la Humanidad, un proyecto diseñado para conocer los alcances de la Inteligencia Artificial (IA), arrojó resultados interesantes en Grok 4, el chatbot del magnate Elon Musk.
Desarrollado por el Center for AI Safety (CAIS) y la empresa Scale A, el denominado Último Examen de la Humanidad, el cual puso a prueba a Grok 4, busca evaluar las capacidades de los modelos de inteligencia artificial, particularmente, en los modelos de lenguaje a gran escala.
Dicha prueba consta de 3 mil preguntas de opción múltiple y respuesta corta, las cuales fueron diseñadas para ser difíciles de responder, incluso para expertos humanos ya que requieren conocimiento profundo y razonamiento.

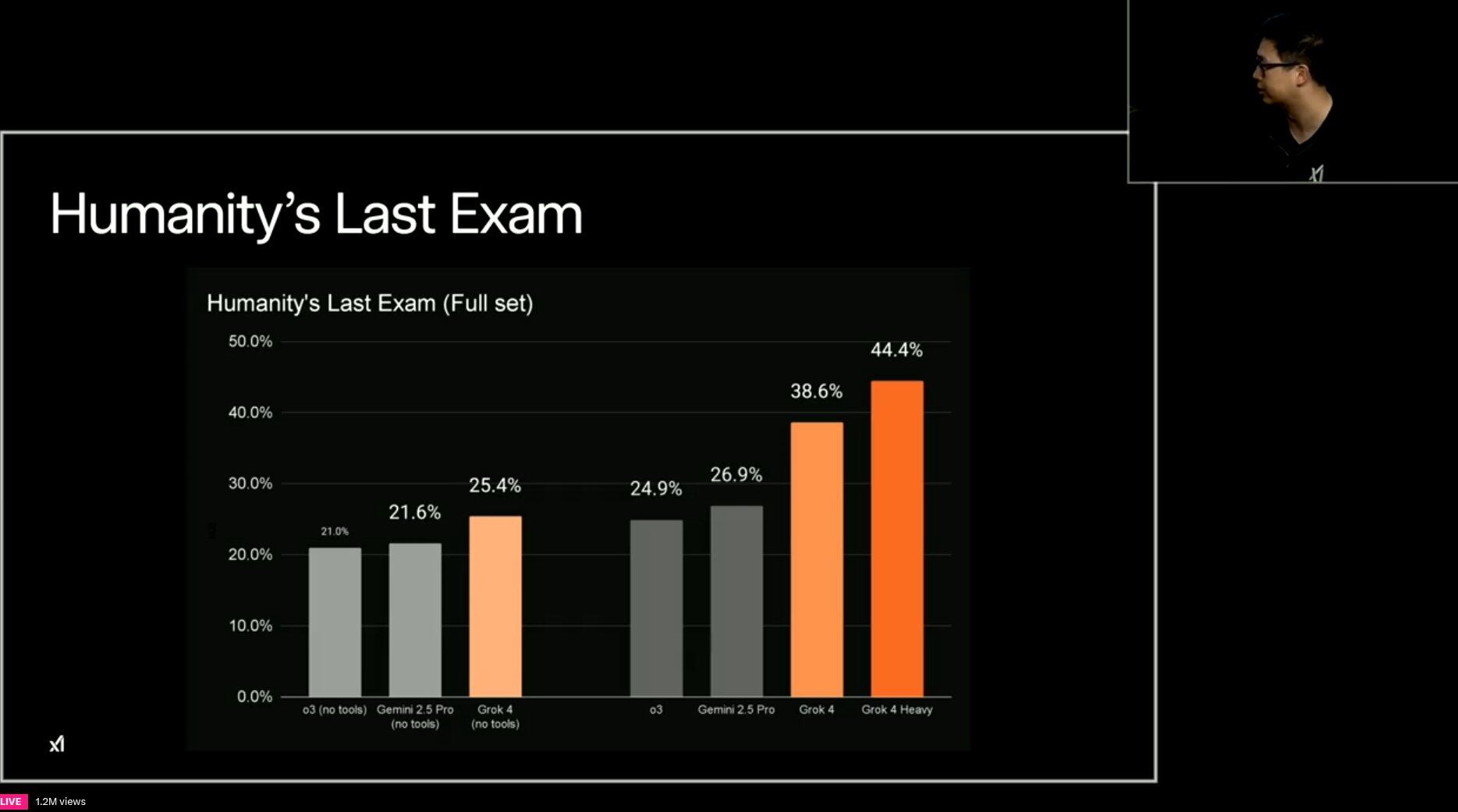
El Último Examen de la Humanidad: Grok 4 alcanzó puntuación de 44.4%
Hoy jueves 10 de julio, en el marco de la presentación de Grok 4 y Grok 4 Heavy, llevada a cabo por Elon Musk y los directivos de xAI, el nuevo chatbot alcanzó una puntuación del 44,4% en el Último Examen de la Humanidad luego de añadirle herramientas externas.
Sin embargo, Elon Musk reconoció que Grok 4 no cuenta con condiciones para inventar nuevas tecnologías o realizar avances significativos en áreas como la física teórica, pero también dijo que esta capacidad se podría desarrollar muy pronto.



“Creo que podría descubrir nuevas tecnologías tan pronto como este mismo año, y sería una sorpresa si no lo hiciera el próximo año”
Elon Musk
En cuanto al Último Examen de la Humanidad, el magnate señaló que Grok 4 es “parcialmente ciego” al ver limitados sus alcances para comprender y generar imágenes, por lo que afirmó que se está trabajando para mejorar el rendimiento del chatbot en este campo.
Por su parte, Google Gemini 2.5 Pro obtuvo una puntuación de 26,9% con la misma configuración.
En dicho contexto, el ingeniero Rohan Paul compartió la siguiente imagen con resultados de diferentes modelos de IA en la prueba, en la cual destacó el caso de Grok 4:
¿Qué es el Último Examen de la Humanidad?
El denominado Último Examen de la Humanidad fue diseñado por cerca de 1,000 expertos de más de 500 instituciones en 50 países, a fin de evaluar las capacidades de razonamiento avanzado de la IA.
La prueba abarca más de 100 disciplinas, entre las que destacan:


- Matemáticas
- Biología y medicina
- Informática
- Física
- Humanidades y ciencias sociales
- Química
- Ingeniería
En este sentido, el Último Examen de la Humanidad cuenta con preguntas dirigidas a personas con un nivel académico de doctorado o aún superior, por lo que se requiere de un razonamiento complejo y análisis profundo para llevar a cabo la prueba, pues esta no puede responderse fácilmente o mediante consultas en Internet.
Algunos elementos multinodales del examen son imágenes y gráficos o tablas, los cuales dan una complejidad aun mayor a la prueba.
La preguntas fueron elegidas a partir de un total de 70,000 candidatas, a fin de poner la prueba lo más difícil posible, aún para modelos de IA avanzados.
El Último Examen de la Humanidad: Modelos más avanzados de IA podrían alcanzar 50% de precisión en 2025
Grok 4, de Elon Musk, señala que los modelos más avanzados de IA alcanzaron puntuaciones muy bajas en el denominado Último Examen de la Humanidad, tal es el caso de OpenAI o1 (8.3%), DeepSeek-R1 (9.4%), GPT-4o (3.3%) y Grok-2 (3.8%).
Sin embargo, destaca el caso de OpenAI Deep Research, el cual alcanzó un 26.6% de precisión, por lo que Grok 4 afirma que antes finalizar 2025, los modelos de inteligencia artificial más avanzados podrían llegar a un 50% de precisión.